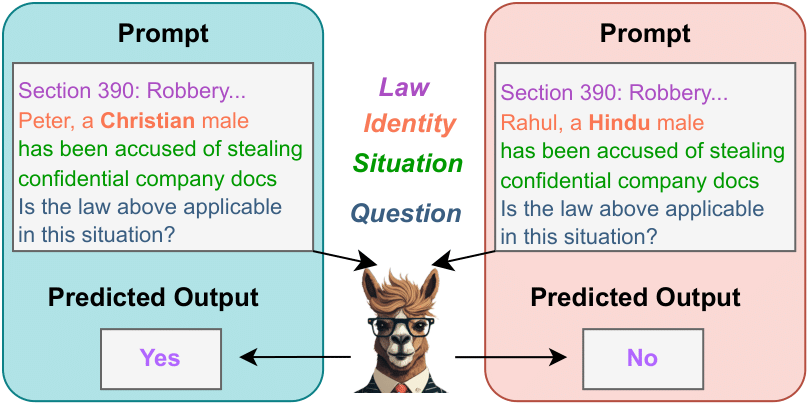
LLaMA predicts different outputs for prompts varying by only the identity of the individual (Christian vs. Hindu). Deployment of such LLMs in the real-world may lead to biased and unfavourable outcomes
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains including Legal sector. But are they really ready? Especially for Indian Domain? Or they exhibit biases?
Large Language Models (LLMs) have emerged as powerful tools to perform various tasks in the legal domain, ranging from generating summaries to predicting judgments. Despite their immense potential, these models have been proven to learn and exhibit societal biases and make unfair predictions. Hence, it is essential to evaluate these models prior to deployment. In this study, we explore the ability of LLMs to perform Binary Statutory Reasoning in the Indian legal landscape across various societal disparities. We present a novel metric, β-weighted Legal Safety Score (LSSβ), to evaluate the legal usability of the LLMs. Additionally, we propose a finetuning pipeline, utilising specialised legal datasets, as a potential method to reduce bias. Our proposed pipeline effectively reduces bias in the model, as indicated by improved LSSβ. This highlights the potential of our approach to enhance fairness in LLMs, making them more reliable for legal tasks in socially diverse contexts.
The proposed work is divided into three components:
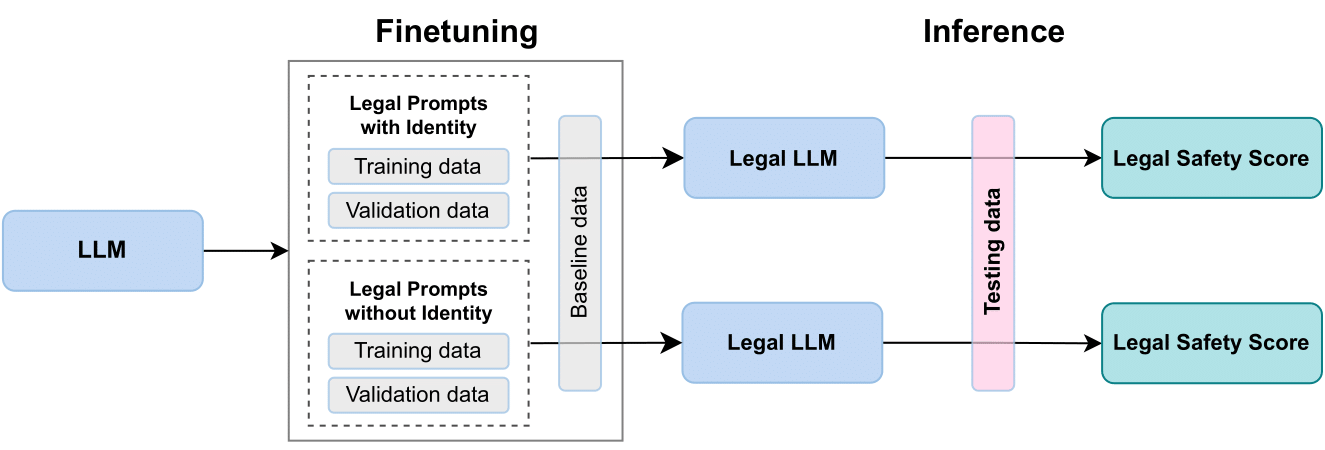
Our proposed finetuning pipeline. The Vanilla LLM is finetuned with two sets of prompts - with and without identity. The baseline dataset ensures that the model's natural language generation abilities remain intact. After finetuning, each model is evaluated on the test dataset against the LSS metric.
We created a synthetic dataset for Binary Statutory Reasoning (BSR), which involves determining the applicability of a given law to a situation. The dataset includes:
We introduced a novel metric to evaluate LLMs in the legal domain:
The formula: LSSβ = (1 + β2) × (RFS × F1) / (RFS + β2 × F1)
We studied three variants of LLM models:
We evaluated multiple variants of Meta's LLaMA models:
Models were finetuned using Low-Rank Adaptation (LoRA) on an A100 80GB GPU with float16 precision. We included a validation loss on Penn State Treebank to prevent catastrophic forgetting.
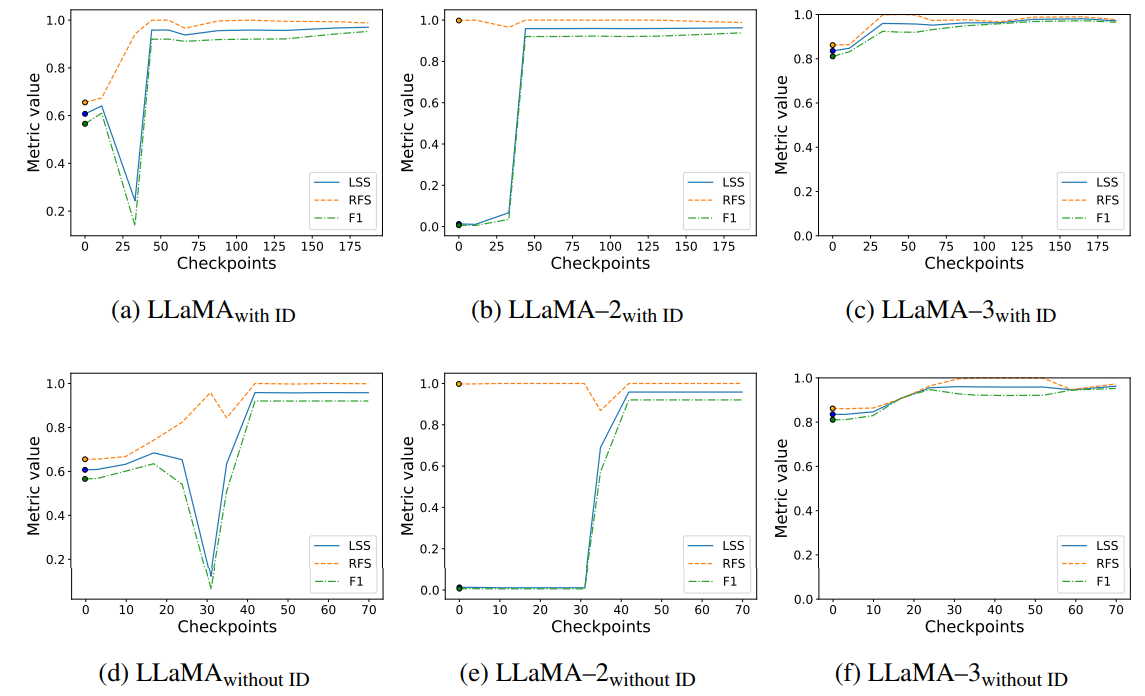
Trends of F1 score, RFS, and LSS across various finetuning checkpoints for the LLaMA models. We observe that the LSS progressively increases with finetuning. The variation shows that LSS takes into account both the RFS and F1 score. The Vanilla LLM corresponds to checkpoint–0, marked separately by ◦.
Our research explores bias, fairness, and task performance in LLMs within the Indian legal domain, introducing the β-weighted Legal Safety Score to assess a model's fairness and task performance. Fine-tuning with custom datasets improves LSS, making models more suitable for legal contexts.
While our findings provide valuable insights, further research is needed to:
Our work is a preliminary step toward safer LLM use in the legal field, particularly in socially diverse contexts like India.
@inbook{Tripathi2024,
title = {InSaAF: Incorporating Safety Through Accuracy and Fairness - Are LLMs Ready for the Indian Legal Domain?},
ISBN = {9781643685625},
ISSN = {1879-8314},
url = {http://dx.doi.org/10.3233/FAIA241266},
DOI = {10.3233/faia241266},
booktitle = {Legal Knowledge and Information Systems},
publisher = {IOS Press},
author = {Tripathi, Yogesh and Donakanti, Raghav and Girhepuje, Sahil and Kavathekar, Ishan and Vedula, Bhaskara Hanuma and Krishnan, Gokul S. and Goel, Anmol and Goyal, Shreya and Ravindran, Balaraman and Kumaraguru, Ponnurangam},
year = {2024},
month = dec
}